Big and Small Models in Robotics: A Hybrid Architecture
Adopt a layered, multi-model architecture in robotics that pairs large, high-level models for complex reasoning with fast, specialized models for real-time perception and control, with coordinated handoffs to balance latency, capability, and safety.
Elsewhere, I’ve talked about one of the first applications I played around with using the GPT-4 vision model: experimenting with how it could be used for machine vision—basically, helping a robotic system navigate its environment or identify objects.
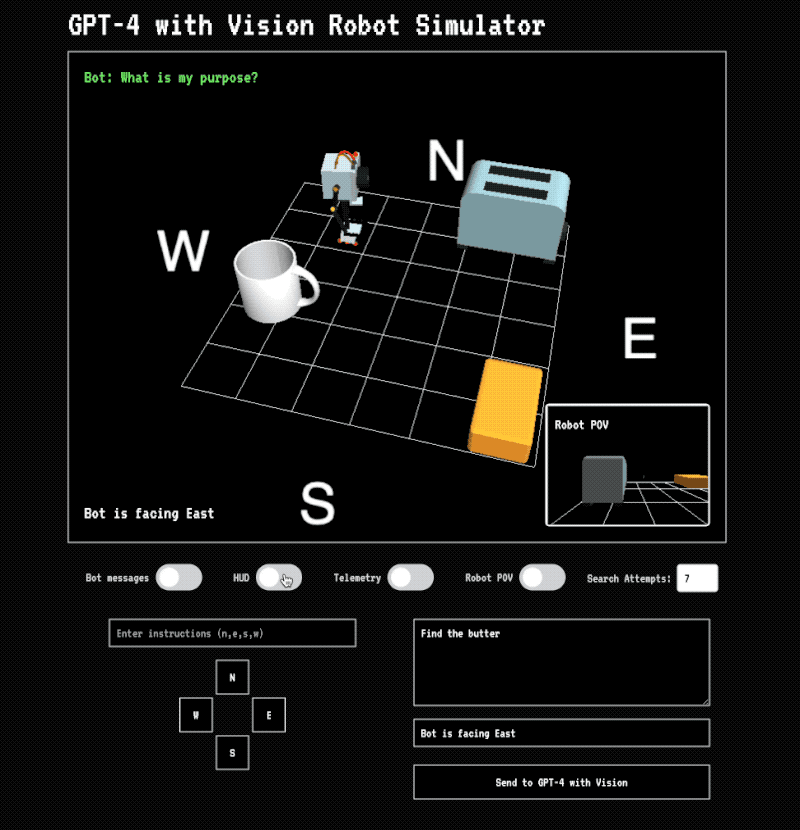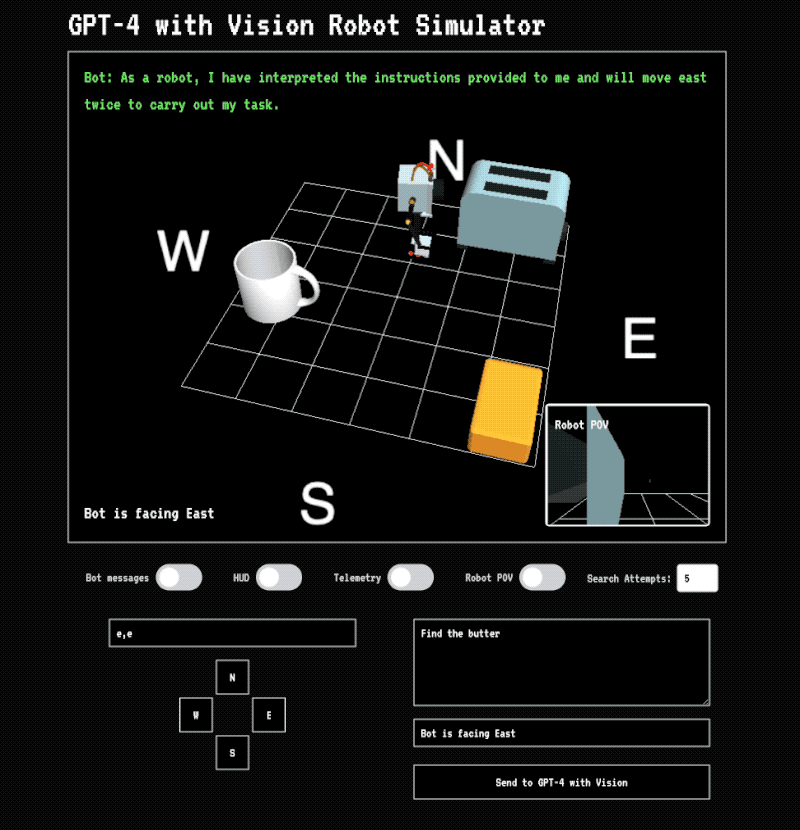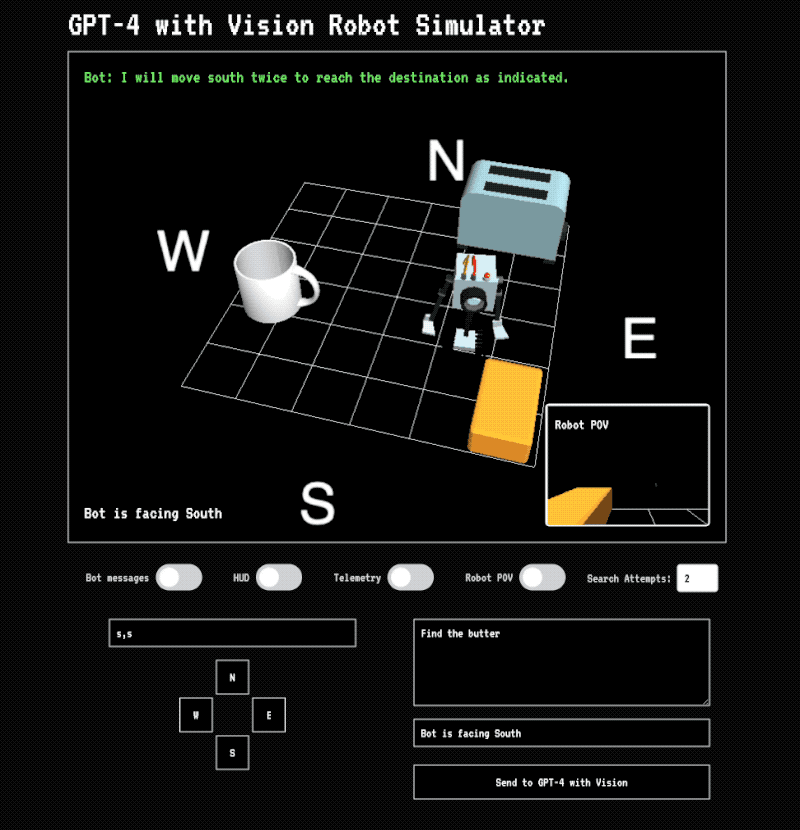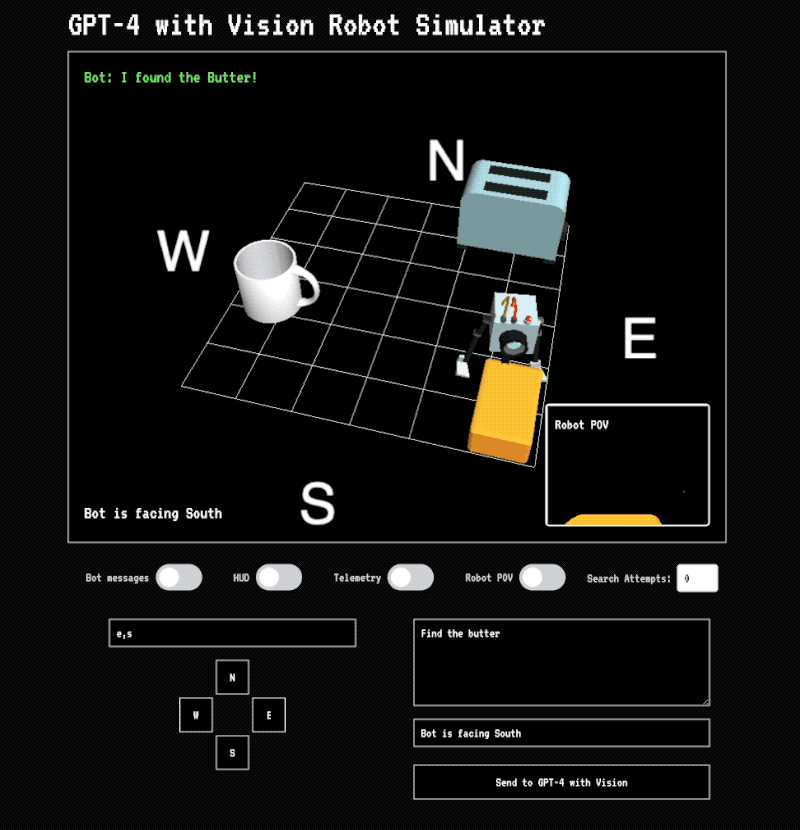
We’re already seeing this in the real world with companies using a hybrid approach: a big model for complex understanding (like recognizing that your kitchen is on fire, or confirming “yes, that’s the object you’re looking for” and what to do next), and other faster, smaller systems for the tight, practical loops—locating specific items in a scene, tracking motion, or figuring out how to move through an environment.
One of the problems with the largest models is latency. They can take time to compute. That said, we’re starting to see some pretty interesting results from systems designed for fast inference. You’ve got things like Cerebras (very large chips that can push a lot of compute quickly). OpenAI has started using that for their Codex Spark model, which is supposed to be something like 15x faster than their other code models. And we’ve seen similar fast-inference approaches from Groq, which also just made a big licensing deal with Nvidia. These kinds of systems matter a lot in robotics, because in robotics you often have to make decisions fast.
And that ties into the broader idea: use the deeper, more complex systems for the “big” problems, and smaller, faster models for the “small” problems.
There’s also a category people call VLA—vision-language-action models. The basic concept is: the robot sees, does some lightweight reasoning, then chooses and executes actions. In other words, navigate around, pick up objects, interact with the environment—without needing to run everything through the slowest, most expensive “think really hard about it” pipeline.
This hybridization approach also maps pretty well to how humans work. We have responses that are basically reflexive—we don’t think about them. If I see a spider out of the corner of my eye, I’m not going to stop and have a conversation with myself. I’m going to flick it off right away. Robotics in real environments is going to need a similar split between reflexive control and higher-level deliberation.
So when you look at a next-generation robot, you’re probably going to see multiple models working inside that system. When it’s having a conversation, it might use a larger model—say GPT-5—for thoughtful responses. But when it’s walking through the living room, it’ll be running a simpler system focused on “don’t bump into the couch.” And when you ask it to pick up your keys off the table, it may use yet another specialized system that understands hand motion, grasping, and object manipulation—while still leaning on a higher-level model for judgment calls and safety, to make sure it’s not doing something it shouldn’t be doing (like, I don’t know, pulling the pin out of a grenade… why do you have a grenade?).
But the point is: we’re almost certainly heading toward multiple models inside one system. And we can already see the early versions of this in software today—tools that use a big model to solve the hard problem, and smaller models for code completion, searching codebases, or sub-agent functions.
I don’t think it’s going to be one big model that does everything. It’s going to be several models that work together depending on the task. And getting them all to collaborate cleanly—deciding who does what, when, and how they share context— is going to be an interesting challenge.